If there is one thing that keeps me awake at night, it is multivariate calculus. The gradient formula always struck me as suspicious in how plain it looks:
You could practically guess it. Partial derivatives are numbers, there is one per coordinate, so you stack them in a list and see what comes out. The thing that comes out happens to point in the direction of fastest change, with a length equal to that maximum rate.
Run that recipe on a real landscape — the two hills below. The formula for their height is a bit of a mess, but the recipe only ever needs its two partial derivatives.
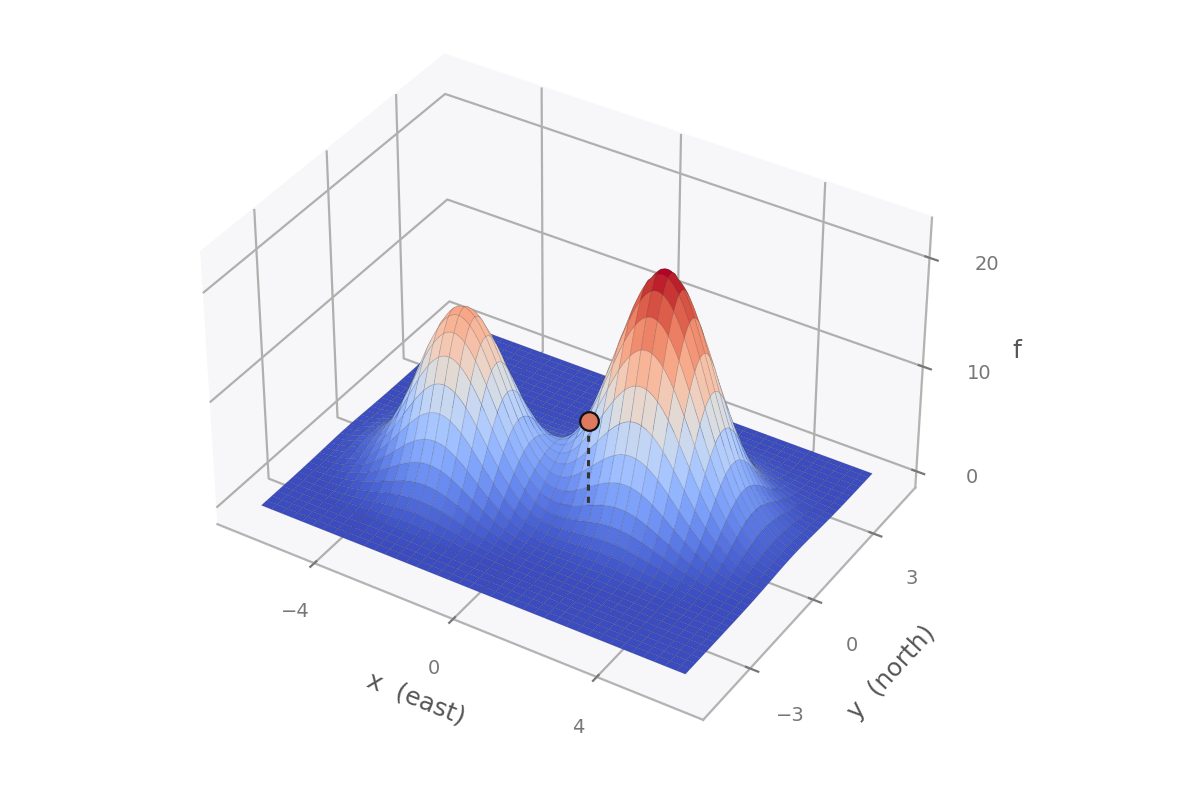 You are here — the spot where we read the two slopes.
You are here — the spot where we read the two slopes.
Stand anywhere and read two numbers: the slope as you step east, , and as you step north, . At the marked spot they come out to 6.4 and 5.2. Stack them into the pair (6.4, 5.2).
That pair, read as a vector, turns out to be an arrow pointing straight up the steepest slope. Nothing in the recipe mentioned “uphill,” or even “direction” — we read two slopes, stapled them into a list, and the list came out knowing the steepest way up.
And nothing about that spot was special. Move anywhere on the landscape and do the same thing: read the slope east, read the slope north, stack them. At (1.5, 2.0), just north of the taller hill: (3.6, -9.4). At (-1.0, -2.5), below the lower one: (-2.0, 3.5). At (-3.5, -1.0), out to its west: (8.1, 1.1). Every spot has its pair, and every pair points straight up the steepest slope there.
To me this always felt like magic: the whole geometry of steepest ascent, falling out of a list. That gap, between the playfulness of the construction and the depth of the result, is what this post is about.
What we will need
You will need three small ideas about arrows — none of them new if you have ever pointed at something — and one from calculus.
An arrow has a direction and a length. Both carry meaning. Velocity is an arrow (a speed plus a direction). A displacement on a map (“two right, three up”) is an arrow. Anything with a direction and an amount can be drawn as one.
![]() An arrow: a direction plus a length.
An arrow: a direction plus a length.
Two arrows from the same origin are either pointing the same way, or perpendicular, or somewhere between. That “somewhere between” is a single number once we have a name for it. For now, we just need the picture: same direction is full overlap, ninety degrees is none.
 Same way, somewhere between, or perpendicular.
Same way, somewhere between, or perpendicular.
Any arrow can be written as a sum of pieces along directions you choose. “Two right, three up” is already this idea. The chosen directions get a fancy name (basis vectors), but you already do this every time you read a map.
A partial derivative is the slope along one chosen axis. Say is the height of a hill above the map point . To find how steep it is left-right, hold fixed and watch how changes as moves — that single-variable slope is the partial derivative, . Left-right almost certainly isn’t the steepest direction on the hill. It’s just a direction you happen to care about, and the partial derivative answers “how steep, this way?” for the way you picked. Ordinary calculus, taken one coordinate at a time.
That is everything we need. Now we can put them to work.
On the slope
Picture yourself standing on a ski slope. There is one direction in which the slope falls away fastest, the line a dropped ball would follow. Plant your skis across (perpendicular to) that line and you stand still: zero change in height as you slide along the skis. Every skier knows this without writing anything down. My daughters learned it the hard way, hunting for the safest position to stand up from after every fall.
 Plant your skis across the fall line and the altitude needle stops.
Plant your skis across the fall line and the altitude needle stops.
Before you push off, pick any direction to slide in — it doesn’t matter which. Slide nearly along your skis and you barely pick up speed; aim them down the mountain and you race away. The same rule governs how fast you lose height: point along the skis and the altitude barely moves, point downhill and it drops. Either way, the direction you picked — and every other one you could have picked — breaks into two pieces: one along your skis (across the slope, so it changes nothing), one along the steepest line (changes everything you are going to change). Only the second piece moves the altitude needle, and how much it moves depends only on how long that second piece is.
Slow down here — this is the whole trick.
Imagine sliding toward a pine tree downhill from you. An arrow runs from your skis to the tree:
 One direction, picked at random: the line from you to the tree.
One direction, picked at random: the line from you to the tree.
That one arrow is really two, laid head to tail: some distance along the no-change direction, where the altitude holds, then some distance straight down the fall line, where all the dropping happens.
 The same arrow, split in two: along the skis, then down the fall line.
The same arrow, split in two: along the skis, then down the fall line.
The length of that downhill piece is exactly how much your direction points down the fall line rather than across it — how much it lines up with the steepest one.
So the rate of change in any direction you pick is just that overlap. Full alignment, full rate. Perpendicular, nothing. Everything else, in between.
The arrow along the steepest direction, with its length equal to that maximum rate of change, is what we call the gradient. That is the whole definition. And this one arrow holds every rate of change, not just the steepest: any direction you pick splits the same way your slide to the tree did, and it changes your height only as much as it lines up with the gradient.
“How much two arrows line up” has a name: the dot product. So the rate of change of in any direction is how much lines up with (the gradient). The formula is how we write that down:
(Here has length 1, to keep the formula tidy.) Do not overthink the formula. It is just the alignment, in symbols, and you could have written it down yourself.
Point along the gradient and , so the rate of change is the full , the maximum. Point it along your skis and the rate is zero. The magnitude of the gradient is the max rate of change. Its direction is where that max happens.
This is what the whole post is about: to know the steepness in any direction, ask how aligned that direction is with the gradient. Everything else here is bookkeeping on this one fact.
From arrow to array
The gradient, the way we have just built it, is a geometric object. It points somewhere on the slope and has a length. What it does not yet have is coordinates. For that, we pick Cartesian axes. Let and be the unit vectors along and .
To find the coordinates of along these axes, you project it onto each one: the -th coordinate is . That is what “coordinates” means here.
The dot product is symmetric, , so is the same number as .
The gradient just changed jobs. A moment ago it was the thing being decomposed, the arrow we wanted to write in coordinates. Now it is the probe: dot it with any vector and out comes the rate of change of in that direction. Apply it to and you get the rate of change of along the -th coordinate axis.
The rate of change of along a coordinate axis is the partial derivative from our list: hold the other variables fixed, wiggle the one along that axis, .
Chain the three steps together — project, swap, probe:
One step per equals sign. The first is the projection: a coordinate is a dot product with an axis. The second is the swap, , because . The third is the probe: hand the gradient an axis and out comes the partial. The swap is the gradient changing jobs — to its left it is being decomposed, to its right it is doing the work.
The array of partials is the gradient read out in Cartesian coordinates. Turn the axes to a different orientation and the two numbers change — but the arrow they describe doesn’t.
 The same gradient, read out in Cartesian coordinates — one partial per axis.
The same gradient, read out in Cartesian coordinates — one partial per axis.
Tricks and miracles
We started with the geometry of steepest ascent falling out of a list, and I called it magic — a mechanical miracle, too good to be true. It isn’t.
The trick is the dot product, and the gradient quietly changing jobs inside it. Project the gradient onto an axis and you get one of its coordinates. Check how fast changes along that same axis and you get a partial derivative. Those sound like different questions, but it is the same dot product read in opposite orders, and the dot product is symmetric — so they land on the same number. The gradient has switched from the thing being measured to the thing doing the measuring. One number doing two jobs.
So stacking the slopes was never a lucky guess. Do it and you are writing the gradient down in coordinates, whether you meant to or not.
Discuss this post on Hacker News, X, or LinkedIn.