I created an AI math reasoning benchmark using puzzles from this year’s GMIL competition—a long-running international mathematical challenge that I participated in myself back in 1998. The results are quite interesting: some of the most advanced AI models performed comparably to my 11-year-old daughter, while others struggled significantly. This experiment gives some amusing insights into current AI capabilities in mathematical reasoning, especially when compared to human performance at the middle school level.
GMIL is an international math puzzle competition organized by Wrocław University of Science and Technology. My daughter, Anika, who is quite fond of these puzzles, submitted her solutions earlier this week, just before the deadline on January 31. After reviewing her solutions, I’m pretty sure she got 7 out of 8 correct. This made me wonder: how would current advanced reasoning models perform on these tasks? It turned out to be a nice idea for a new weekend project, and after a few hours, I had my own curated AI reasoning benchmark which I call GMIL CM Benchmark - Math Reasoning as a 11-Year-Old. Let’s see the results!
 Anika at GMIL Finals, 2024
Anika at GMIL Finals, 2024
The Competition
The GMIL (Gry Matematyczne i Logiczne, or Mathematical and Logical Games) is the Polish branch of the international FFJM competition, and both share the same format. The puzzles are divided into categories with increasing difficulty. The youngest participants (category CE—up to 9 years old) solve the initial few puzzles, while the most advanced (professional mathematicians or STEM university-level students) are expected to solve all the puzzles on the list. The competition has a long history, dating back to 1987, and I remember participating in it as a teenager with some success—I was one of the finalists of the Polish edition back in 1998. It’s both inspiring and scary to see both my daughter and the new AI models now capable of solving puzzles that I found quite challenging back then.
The Puzzles
For my benchmark, I was only interested in the puzzles from the CM category, which Anika participated this year. Here are all the puzzles, translated from Polish to English:
1. Two Dates
Mateusz has 12 cards with digits:
0 0 1 1 2 2 3 3 4 4 5 5
and he arranges them to form dates. The first date of 2025 that he can create using two cards to form the day number, two other cards to form the month number, and four other cards to form the year number will be January 13:
1 3 0 1 2 0 2 5
What will be the last date in 2025 that Mateusz can create using eight of these twelve cards?
2. Aquarium
In the aquarium, there are octopuses with eight arms and starfish with five arms.
How many starfish are there in the aquarium if the total number of arms of all the animals living in it is 41?
3. In the Maze
In the maze, the rooms are numbered from 0 to 15. Moving between rooms triggers an alarm, except when:
- Moving to a room with a number exactly 3 greater than the current room, or
- Moving to a room with a number exactly 13 less than the current room.
We enter the maze through room number 0 and exit through room number 1.
How many rooms will we pass through (including rooms 0 and 1) if we never trigger the alarm along the way?
Maze Layout:
9 12 15 2
6 7 4 5
3 10 11 8
0 13 14 14. Race to 2025!
G N A J
+ N A
-----------
2 0 2 5In this coded addition, different letters represent different digits, and the same digit is always represented by the same letter. Additionally, none of the multi-digit numbers start with zero.
What is the value of NA?
5. Four Friends
Anna, Bartosz, Cezary, and Danuta are four friends. Each of them is preparing for a specific profession: archaeologist, bookkeeper, carpenter, and dentist. It is known that Bartosz will be a dentist. Only one of these people is training for a profession that starts with the same letter as their name, and that person is not Anna.
What professions did Anna and Danuta choose?
6. The Lost Scale Pan
Robert lost the right pan of his balance scale and had to use a different one—slightly heavier than the original. Now, with empty pans, his scale does not show balance.
However, Robert noticed that when he places a full bottle of juice on the right pan and 9 identical empty bottles on the left pan, the scale is balanced.
The same happens when Robert places two empty bottles on the right pan and a bottle filled halfway with juice on the left pan.
How many times heavier is the full bottle of juice compared to an empty bottle?
7. On the Plus Side
_ _ _ _ _ _Place all the numbers 1, 2, 3, 4, 5, and 7 in the boxes in such a way that the first number is smaller than the last, and in every set of three consecutive boxes, there are two numbers and their sum.
8. Hats
Pola has a pair of plush monsters: a three-headed Cerberus and a two-headed Dragon. She really enjoys playing with these plush toys by putting hats on their heads. Pola has four identical white hats, two identical green hats, and one red hat. It is known that each of these hats can be placed on any head of Cerberus or the Dragon.
In how many different ways can Pola put the hats on her plush toys so that each head has exactly one hat?
Two ways of putting on the hats are considered different if the hats on at least one head of one of the plush toys are of different colors.
The full set of 18 puzzles is available as a PDF online. You can also browse through the archives to see all the puzzles (from all stages) from 2002 till today. It’s quite an impressive collection!
Methodology
For my benchmark I selected the advanced reasoning models from various providers:
- GPT-4o: My usual go-to model from the OpenAI family, with access to code execution.
- GPT-o3-mini: The new OpenAI model made available just yesterday.
- Sonnet-3.5: My go-to model from Anthropic, sometimes referred to as Sonnet-3.6.
- Gemini-Flash: Google’s advanced reasoning model optimized for speed.
- DeepSeek-R1: A state of the art reasoning model from DeepSeek.
I used the standard chat interface rather than the API directly. For each model, I provided identical puzzle descriptions and allowed one attempt to solve each problem. I evaluated their responses against the correct solutions, counting a solution as correct only if the final answer matched exactly. A GitHub repository with puzzles, solutions and transcripts is available online. I welcome contributions and results from other models: GPT-o1 family, Gemini Flash 2 Thinking, Fireworks F1 or others. Just PR on GitHub or DM me on X or LinkedIn if you want to share your results.
Benchmark Results
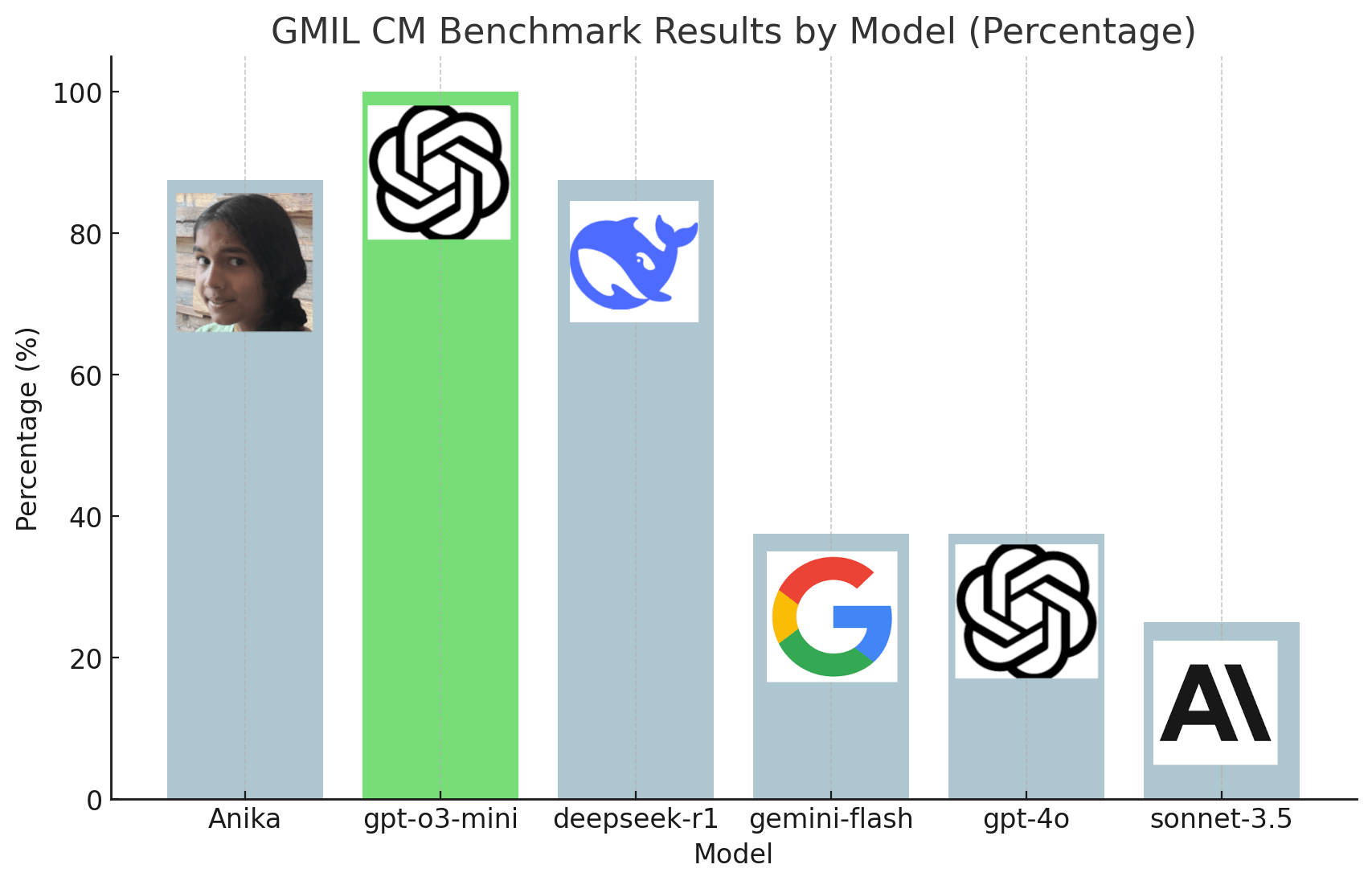
The benchmark results reveal a clear separation in mathematical capabilities among the tested models. At the top tier, three performers stand out: GPT-o3-mini achieved a perfect score of 100%, while both my daughter Anika and DeepSeek-R1 solved 7 out of 8 tasks correctly (87.5% accuracy). In contrast, Gemini-Flash and GPT-4o each solved 3 tasks, while Sonnet-3.5 managed only 2 correct solutions.
DeepSeek-R1’s performance deserves a closer look, as its approach often relied heavily on brute-force computation, systematically testing all possible solutions. This strategy proved successful for simpler puzzles like Two Dates, where the solution appeared early in the search space. However, when attempting On the Plus Side, R1 exhausted its inference tokens before finding the answer. While it might have eventually succeeded with more computational resources, I counted this as a failure in the final results.
Below are the results for each model, with links to the solution transcripts. Unfortunately, I don’t have Anika’s notes anymore but you can take my word for it—she did solve 7 on her own :)
GPT-4o
- Correct: Aquarium, Race to 2025!, Four Friends
- Incorrect: Two Dates, In the Maze, Lost Scale Pan, On the Plus Side, Hats
Total Correct: 3
GPT-o3-mini
- Correct: Two Dates, Aquarium, In the Maze, Race to 2025!, Four Friends, Lost Scale Pan, On the Plus Side, Hats
Total Correct: 8
Sonnet-3.5
- Correct: Aquarium, Four Friends
- Incorrect: Two Dates, In the Maze, Race to 2025!, Lost Scale Pan, On the Plus Side, Hats
Total Correct: 2
DeepSeek-R1
- Correct: Two Dates, Aquarium, In the Maze, Race to 2025!, Four Friends, Lost Scale Pan, Hats
- Incorrect: On the Plus Side (ran out of tokens)
Total Correct: 7
Gemini-Flash
- Correct: Aquarium, Race to 2025!, Four Friends
- Incorrect: Two Dates, In the Maze, Lost Scale Pan, On the Plus Side, Hats
Total Correct: 3
Anika
- Correct: Two Dates, Aquarium, In the Maze, Race to 2025!, Four Friends, On the Plus Side, Hats (no transcripts available)
- Incorrect: Lost Scale Pan
Total Correct: 7
What’s next?
One interesting aspect of this benchmark is that these puzzles are most likely new, and solutions are not yet available online. For all previous editions, Wrocław University actually publishes the solutions, so they may be included in the training data. Even with new puzzles, the models might still perform well through memorization. Many problems, particularly in the lower difficulty categories, follow familiar templates that models could match against similar historical problems. If memory fails, they can always try to brute force through all the options, just like 4o did with Race to 2025!, leveraging its ability to generate Python code:
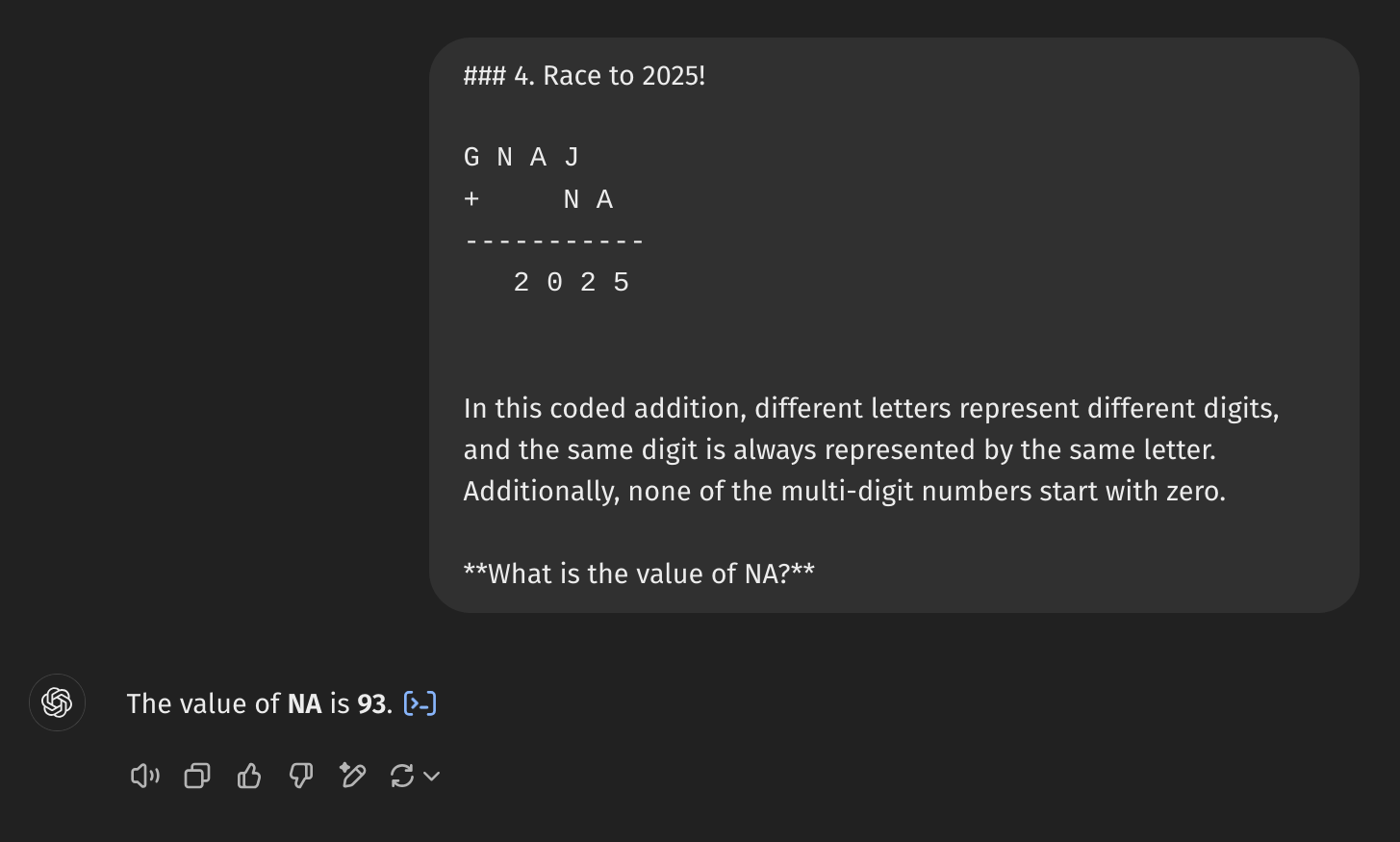
It would be fun to extend this analysis to more difficult GMIL categories and perhaps create a standardized version of this benchmark for tracking AI progress in mathematical reasoning. But for now, I’m leaving this with a mix of pride and fascination that my daughter’s math skills are comparable to DeepSeek’s R1—for better or worse.
Big thanks to my friends Michał Warda, Łukasz Wróbel and Tomek Gancarczyk who inspired me to write this.