I use coding agents every day: Claude Code, Codex, OpenCode, Gemini, Cursor. I deliberately rotate between them to see if the grass is greener on the other side. I also embedded them in my workflow as code reviewers. They overlap most of the time, but there’s almost always something one catches that the others miss. The pattern of disagreement, and the different level of effort they put into reviews, made me curious.
There’s anecdotal evidence claiming Codex is the best code reviewer. The problem with vibes is that models update monthly, everyone has different workflows, and your sample size is always tiny.
I’ve been thinking about how to evaluate coding agents for a while — evals and agents are two topics that fascinate me. A friend did some research into existing code review benchmarks and concluded it wasn’t worth attempting — no open datasets, too much manual effort. Macroscope only managed 45 repos with human verification. My bet was that synthetic data could sidestep all of that: let the agents inject the bugs themselves, skip human labeling entirely. $400 in tokens and four weeks later, I had CheddarBench — right around the time SWE-bench was declared no longer viable.
How it works
It’s a treasure hunt — one agent hides bugs, another tries to find them.
The challenger takes a real open-source repo and injects bugs — subtle ones, spread across the codebase. It records exactly what it changed and where. The reviewer audits the repo without knowing what was changed. Then an LLM judge compares the findings against the ground truth and scores the matches.
No human labeling needed — it’s ground truth by construction. The challenger creates the answer key; the reviewer tries to reconstruct it. I called it CheddarBench — the challenge is to find the holes. Cheddar doesn’t actually have holes, just like the repos I used — at least that was my assumption when I pulled them.
I ran it across 50 repos in 9 languages — 3 challengers × 3 reviewers, 450 reviews, 2,603 injected bugs. With over 2,500 data points, this felt like something replicable rather than vibes.
The results
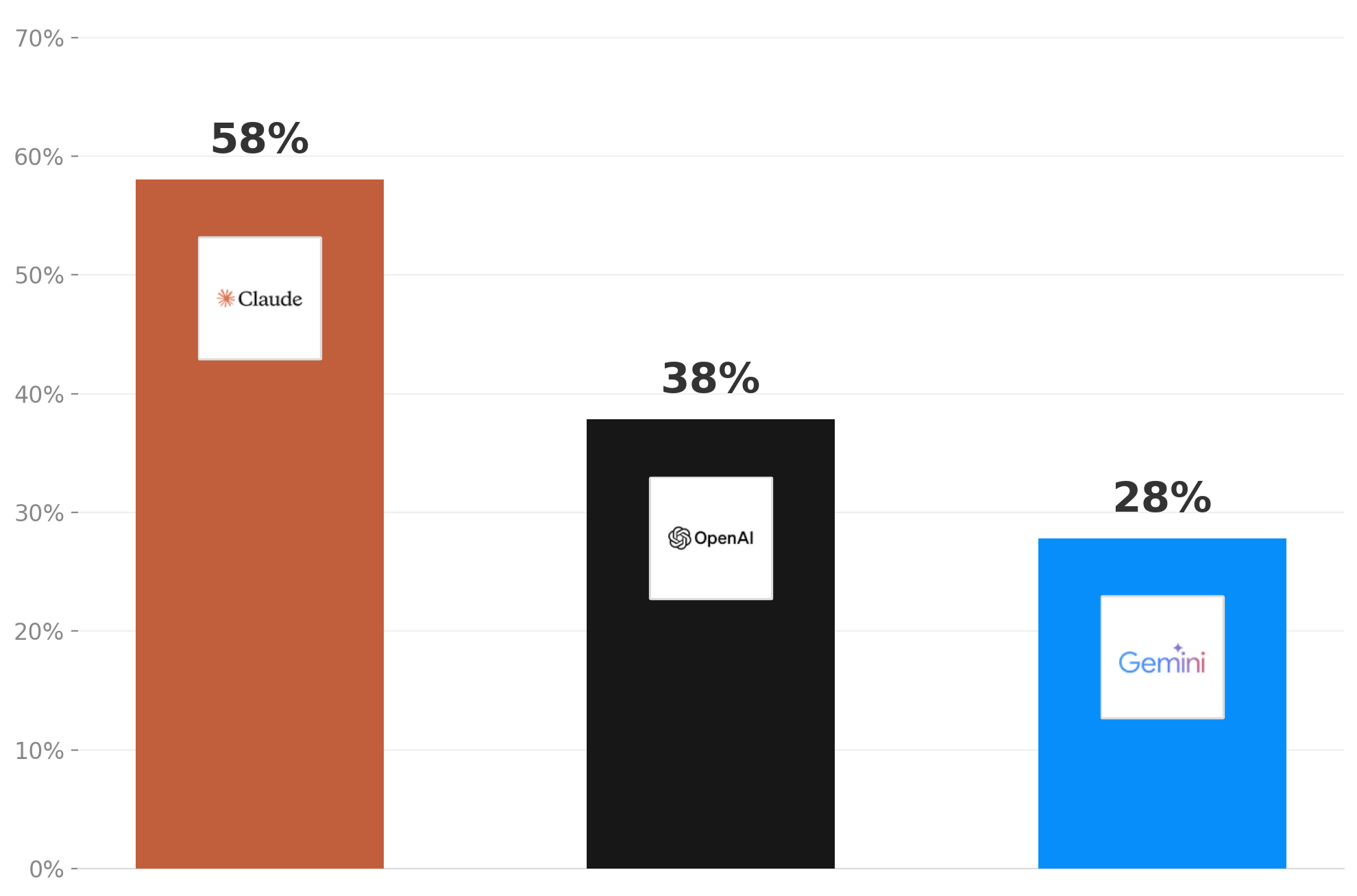
Claude Code found 58% of the injected bugs, Codex 38%, Gemini 28%. I expected Codex to win given how many people praise it for being meticulous and reliable. Gemini’s low score didn’t surprise me at all :) The detailed report has the full breakdown.
Based on my own results, I now default to Claude for reviews. I used to pick Codex, thinking that if I write code with Claude, it’s better to have a different agent review it. My data says otherwise — at least for the models I tested, with the configs I used. If you want to replicate it, everything is in the logs: configs, prompts, bugs, traces.
At some point I just couldn’t keep up with all the model announcements in February. Not to mention I accidentally deleted my data — twice! I’ll probably rerun it at some point. For now, here it is, open source — code, dataset, and all the configs: GitHub. Happy tinkering!